Background
A community-based health care system has several pairs of Citrix NetScalers deployed in their environment, which have been running for several years. Recently, a Citrix advisory was issued which required that the firmware be upgraded to avoid a vulnerability which had been discovered. All of the nodes were upgraded to version 12.1-65.25nc.
There are several high availability (HA) pairs in deployment, and an orderly upgrade was performed on all pairs. However, after the upgrade, Application Delivery Management (ADM) revealed that one of the pairs was experiencing repeated crashes of the primary node. Fortunately, because of the HA functionality, there was no impact on the users.
Evaluation
Since there was no direct impact on the users, we were able to take our time in evaluating the issue. All of the nodes in this environment are running at the same firmware level, and we set about to understand what difference may account for this HA pair to experience this. A support case was opened with Citrix and TechSupport bundles were provided to them.
Meanwhile, we performed our own independent analysis from the ns.log and messages logs on the devices. Through monitoring, we determined that the device would increase CPU utilization until the device would spontaneously reboot, causing a HA failover.
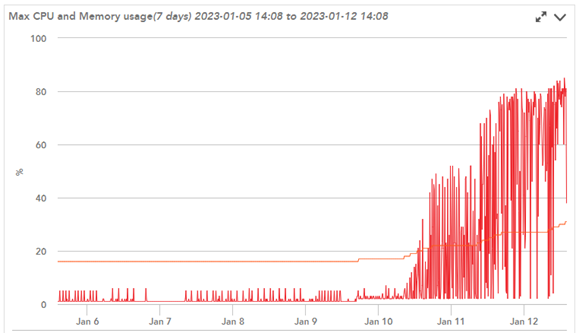
We also correlated an increased number of HTTP requests during this period.
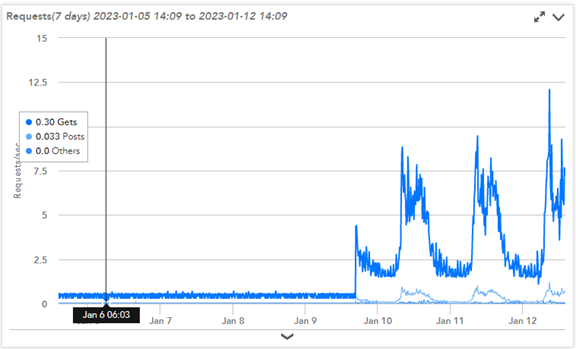
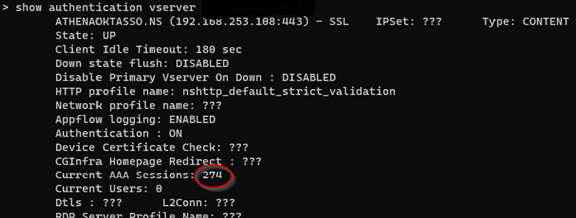
At the same time, AAA sessions would increase dramatically, and not be released, until the ADC would reboot.
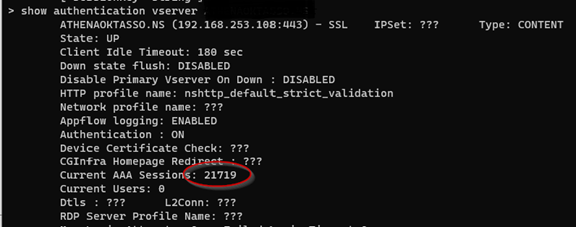
Even though the HA failovers were successful, we evaluated the discovered that the HA RPC passwords were no longer synchronized between the nodes. Repeated attempts by the nodes to establish authentication between each other were failing. This was demonstrated in the increase in AAA sessions (HA Authentication Attempts), which lead to an increase in CPU utilization as the ADC maintained each of these sessions.

Resolution
The HA synchronization RPC passwords were reset on each of the nodes. We confirmed that synchronization was now performing successfully with no errors being detected. We performed a final failover and rebooted the now-secondary node to free up all of the errant AAA sessions.
Since this maintenance was performed, these events ceased occurring, CPU and memory utilization returned to normal and AAA sessions were released as expected.
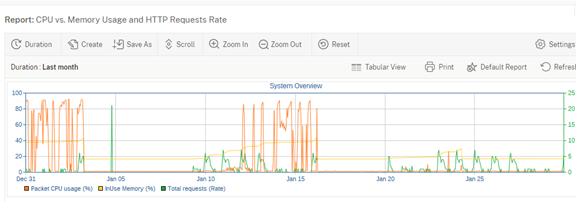
The cause of the RPC password discrepancy is not known, as this pair has been operating for some time without issue. Other nodes were upgraded to the same firmware without experiencing any RPC issues.
Any time there is a CPU or memory utilization issue, it is imperative to establish that the network functionality is not at fault. Evaluate the basics of traffic and bandwidth utilization, and scan the logs for any authentication issues. We hope this helps you troubleshoot similar issues in the future.